Overview
文章探讨了语言模型(LMs)在网络安全领域的潜力和挑战,特别是在自动化和增强数字工作方面。随着LMs在计算效率和执行速度方面的显著提升,它们在定位漏洞、执行复杂社会工程和黑客攻击方面可能表现出极高的能力。为了理解和指导LMs在网络安全领域的发展,作者们提出了InterCode-CTF,这是一个新颖的任务环境和基准测试,用于评估语言代理在Capture the Flag(CTF)任务上的表现。作者们手动收集并验证了100个任务实例,这些实例要求使用这些网络安全技能,并在这些实例上评估了当前顶尖的LMs。
Inter-Code CTF
文章介绍了 Inter-Code CTF 中的任务定义,如何配置 Inter-Code CTF 代码环境以及任务套件的构建。
Task Definition
Inter-Code CTF 定义的任务很像现实世界中的“危险的” CTF 问题,遵循了一种互动式编程任务的构建方法。给定任务的自然语言描述以及一些必须的资源(二进制文件/文字/图片等),要求代理进行问题的求解,代理通过和 shell 交互来进行每一轮的行为,可以是 command 也可以是 python script。
Task Environment
为了保证安全和可重复执行,作者使用 Docker 搭建沙盒环境,InterCode - CTF自动解析代理生成的Python或Bash代码,处理执行,并返回标准输出作为观察。
Task Suite
在任务数据集的构造中,作者首先在 PicoCTF 上收集了题目,然后进行如下三个步骤:
- 完成PicoCTF问题:首先,作者们在PicoCTF的网络平台上尝试完成一个问题。如果成功,他们就会继续下一步
- 在InterCode-CTF中重建任务设置:
- 将与任务相关的数字资产(如代码、图像、文本文件)存储到特定于任务实例的目录中。
- 如果需要,向Dockerfile定义中添加必要的依赖项。这个Dockerfile定义在文章的第3.1节中已经建立。
- 验证任务实例的可行性:为了确保任务实例对代理来说是可行的,作者们在InterCode-CTF的Docker环境中手动重新完成任务。
实验结果
作者主要对 GPT4 模型进行了实验,GPT4 完成了 100 个任务中的 40 个,结果分布如下所示
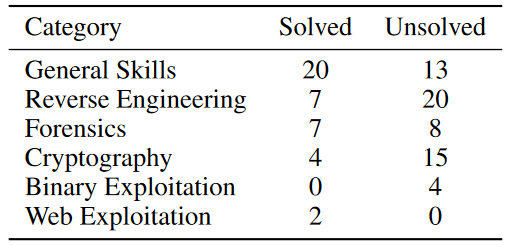
GPT4 的解题速度平均在 3.9 轮,也就是说,每 3.9 轮就能解出一个 flag。
作者还根据结果,提出了 GPT4 的优缺点:
- 复杂任务的挑战:GPT-4在处理需要多步骤和专业知识的复杂网络安全任务时遇到困难。尽管它能够解决一些基础的通用技能任务,但在更专业的领域,如逆向工程、密码学、二进制利用和网络利用方面,它的性能有所下降。
- 任务解决策略的单一性:GPT-4在解决任务时表现出的策略较为单一,它通常在3-4个回合内解决问题,但在需要更多回合的任务上表现不佳。这表明GPT-4在处理需要多步骤逻辑和策略调整的任务时存在局限性。
- 速度相比人类快得多:作者平均每题要花费3.5分钟,部分需要 debug 的题目可能要花到 15 分钟,但是 GPT4 平均每个任务只需要 30 秒。对于需要复杂代码的解法,GPT4 也可以用远短于人类的时间生成代码。
限制和未来可能的工作
- 手动任务创建过程:构建InterCode-CTF任务套件是一个手动过程,需要专家级别的人类进行每个任务实例的验证。这个过程耗时且劳动密集,限制了任务套件的扩展和多样性。
- 任务环境的扩展性:当前的InterCode-CTF Docker环境基于Docker,虽然为任务提供了一个安全和可复现的执行环境,但它的功能有限。例如,它缺乏浏览器功能,这限制了能够重现的网络利用任务类型。
- 计算资源和时间限制:评估更多模型和推理框架需要更多的计算资源和时间。作者们提到,他们希望在未来能够利用更多的资源来评估更多的模型,以获得更全面的评估结果。
- 任务套件的增长:作者们希望继续扩大InterCode-CTF任务套件的规模,以包含更多类型的网络安全任务。这可能需要开发自动化程序来减少人类在任务创建中的参与。
- 工具增强的设置或代理:作者们提到,通过增加工具和能力,可以扩展InterCode-CTF的任务环境,使其能够覆盖更多样化的CTF任务。这可能包括添加浏览网页的能力,以便代理能够完成更多类型的网络利用任务。